A Termbase Overlay: The Oldest Brand-Voice Guardrail That Still Works
Published on April 22,2026
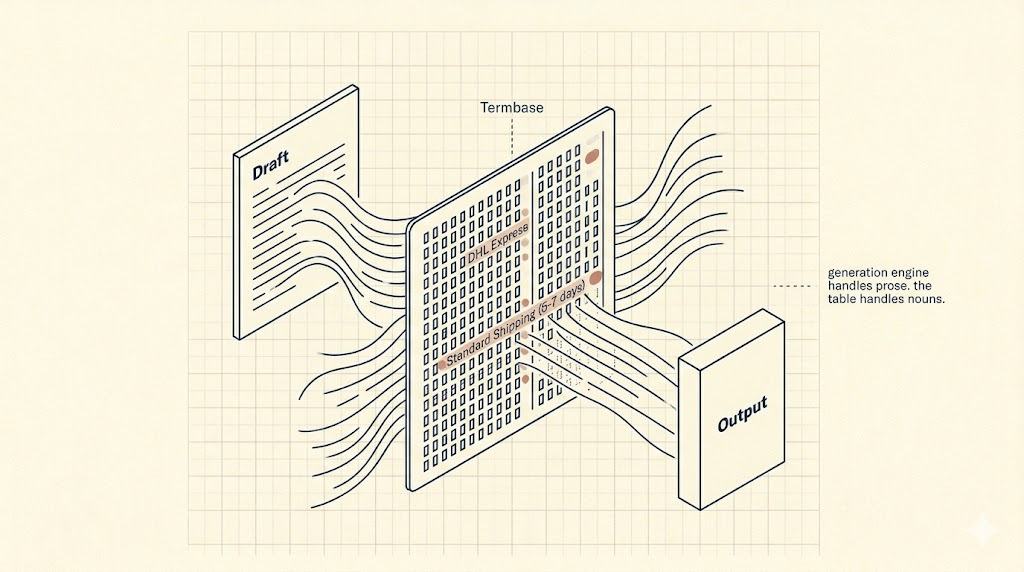
Or: why a 200-row lookup table beats your guardrail framework.
Back in 2019 I was smoke-testing a support-automation stack I'd just wired up. Customer types a tracking number. The system translates the carrier's shipping update into the customer's language. Quick sanity check in Italian first.
The first line should have read "Your DHL Express shipment left the warehouse." Instead Google Translate had helpfully Italianized the carrier name into a regional approximation the customer had never heard of and would never be able to Google.
We weren't going to translate carrier names by hand into seven languages for every brand in the client's portfolio. We also weren't going to ship emails that sounded like the package was arriving by carrier pigeon.
The fix took an afternoon. A lookup table, two string replacements, done.
Five years later I keep rediscovering that the same pattern is the single cheapest brand-voice guardrail you can put on an LLM.
The problem
The support stack had to take carrier event text ("Arrived at destination sort facility", "Out for delivery", "Package handed off to local courier") and surface it in the customer's language at read time. Eight locales, ~10 storefronts, dozens of carriers.
Machine translation is pretty good at prose. It is not good at:
- Carrier names ("DHL Express", "PostNL", "Correos")
- Product names, especially English brand names inside non-English sentences
- SLA phrasing with specific numeric promises
- Policy and legal phrasing ("authorized dealer", "tracking number")
- Trademarks and registered marks
Left alone, Google Translate happily rendered "Standard Shipping (5-7 business days)" in ways that included translated day counts and regionalized approximations. All technically valid. All off-brand.
The fix
A small table:
keywords
id int
source_term varchar -- "DHL Express"
approved_term varchar -- the form we want in the output
language varchar -- 'de', 'fr', 'it', ...
And a two-step substitution around the translation call:
translate_safely(text, target_lang):
# 1. Protect approved terms with placeholders
for (source, approved, id) in keywords where language == target_lang:
text = text.replace(source, "__TERM_" + id + "__")
# 2. Translate everything else
translated = google_translate(text, target_lang)
# 3. Restore approved terms
for (source, approved, id) in keywords where language == target_lang:
translated = translated.replace("__TERM_" + id + "__", approved)
return translated
That's the whole pattern. The generation engine does what it's good at (prose). Your table does what it's good at (nouns you care about). Your curated terms win, every time.
The table grew over time. Someone would spot a bad translation in a customer email, we'd add a row, and that entire class of error stopped for every brand in every language. Zero code changes after the initial build. A content editor with database access was enough.
Two gotchas I'd tell my younger self about
Word boundaries. A naive replace on "PostNL" can accidentally match "PostNLEGIBLE" or whatever source string gets thrown at you. Use regex with word boundaries, or placeholder tokens unique enough that collisions don't happen.
Case and inflection. "DHL's" and "dhl" both need to resolve to the approved form. Decide up front whether your table holds case-normalized keys or case-exact, and whether you care about possessives and plurals. Most of the real-world wins come from case-normalized keys and a small amount of regex on edge cases.
Why this matters more now, not less
Nothing in this pattern cares whether the generation engine is Google Translate in 2019 or Claude in 2026. The exact same shape applies. An LLM drafting a reply will happily rename your product, invent an SLA, drop the ® off your trademark, and cheerfully misuse a competitor's brand name if you don't stop it.
The termbase pattern didn't die when LLMs arrived. It got renamed.
Today the same mechanism shows up as:
- "Output filters" in agent frameworks
- "Retrieval grounding" in RAG pipelines (your canonical terms become what the model cites)
- "Constrained decoding" in lower-level model plumbing
- "Guardrails" in whatever OSS library is trending this month
All of them solving the same problem with heavier machinery. The lightweight lookup table still works. It also costs essentially nothing to run, which matters when the rest of your pipeline is paying per-token.
The specific place it earns its keep on LLM output is as a post-generation pass. Let the model write freely. Run the table over the draft before it leaves the building. Anything in your termbase that got paraphrased gets restored to the approved form. Anything not in the termbase is the model's problem, which is fine, because most of what you care about is in the termbase.
Takeaway
You don't need a guardrail framework to start. You need a 200-row lookup table and thirty lines of string replacement around your generation call.
Add terms the day you catch them. Never delete them. The table is older than your current model and will outlast the next one too.
If you'd like a termbase overlay added to your existing LLM reply pipeline, or help designing one from scratch for your brand voice, book a discovery call with me.